Building a Pagefind UI
One of the fun things about running your own personal website is that you can add things to it that are not strictly needed, but might be interesting to add anyway. While I try to not actually break the basic functionality of the website, I feel more free to add miscellaneous new stuff.
This is how I ended up deciding to add Pagefind-powered search to my website. I assume that people do not regularly visit my website and then find themselves wishing it had a search feature, so that they could use it to locate a particular web log article, considering I have published fewer than 25 of those over the entire time this website has existed. But, it was possible for me to add such a feature, and so I did.
How Pagefind works
Search engine implementations for static websites can generally be divided into two categories: server-side and client-side. With server-side, something has to build an index of all the pages within the site, and then something has to handle search-related HTTP requests by consulting that index. Unlike a static website, such functionality cannot be hosted off a server that simply serves static files over HTTP—the thing that consults the index needs to be able to execute code on the back end, which makes hosting more complicated. This kind of search functionality often ends up outsourced to a third party.
The other option for static website search is moving the search to the client. In the simplest implementation of this idea, the client downloads a search index of the website, along with some JavaScript code capable of using that index. These can be static files, so the server does not have to do anything fancy, but it also means the client has to do more work. While extra CPU cycles and memory use by the client can be an acceptable trade-off, the bigger problem can be transferring the index. Since such an index is essentially the whole website, but in a different shape, it can involve transferring quite a lot of data to the client.
Pagefind solves the index size problem by splitting the index into chunks. While the index is still mostly the whole website in a different shape, the whole index does not have to be downloaded to perform a search. Instead, the client ends up downloading only the chunks it needs to search for the given terms, and to display the relevant results.
Pagefind is implemented as a command line tool, written in Rust. The tool is designed to be operated on a local copy of the site's directory tree of HTML files, and it emits a subdirectory of files which implement the search engine, into that copy. It creates an index of all the pages in the site, while also gathering metadata about each page. It then splits that search index into chunks, and saves those index chunks, as well as the metadata for each page, into individual, compressed files. The tool also emits the client API code—a combination of JavaScript and WebAssembly—as well as an implementation of a search user interface that uses the API.
Running Pagefind from Eleventy
Since I run Eleventy directly, and not from a build system or task runner, I wanted to run Pagefind as part of the Eleventy build process. After version 1.0, Pagefind comes with a Node.js interface, which runs the Pagefind binary, and talks to it over standard input and output. I, however, started working on this problem before Pagefind 1.0 was released, and so I went with the simpler method of invoking the Pagefind binary directly.
Eleventy emits a number of events during a build process. One of those events is eleventy.after, which happens after a build is done (predictably enough). We can hook into this event to run Pagefind on the site, after it's done building:
const util = require("node:util");
const exec = util.promisify(require("node:child_process").exec);
module.exports = (eleventyConfig) => {
eleventyConfig.on("eleventy.after", async ({ dir }) => {
// using promisified exec(), since it's an expedient way to get something
// we can await here
await exec(`npx pagefind --site=${dir.output} --output-subdir=./pagefind`);
});
};An Eleventy plugin that runs Pagefind.
The npm package for Pagefind pulls in a pre-compiled binary (at least for the supported platforms), so we are calling it through npx. Since we do not use Pagefind's Node.js API, we could also provision the Pagefind binary in some other way, get it into PATH, and call it directly. The npm approach is easier, but might be undesirable for situations where building such things locally is preferable.
Adding metadata
Pagefind can store arbitrary key–value pairs of metadata for each page it indexes, and the client API can then be used to access that data for each result it finds. Pagefind stores some metadata by default—for example, the title of a result—and then uses that metadata when rendering results with the default results interface.
Since Pagefind indexes the finished HTML output of a static site, this is also where it gets its metadata from. To indicate to Pagefind where this metadata is, specific data-* attributes can be used. For example, if we wanted to store the datetime attribute of a <time> element under the key date, we would add data-pagefind-meta="date[datetime]" to that <time> element:
<article
class="content fullarticle h-entry"
data-pagefind-body
data-pagefind-meta="kind:weblog"
>
<header>
<h1 class="p-name">Reflashing brain implant firmware</h1>
<div class="metamatter">
<time
class="dt-published"
data-pagefind-meta="date[datetime]"
datetime="2035-10-03T03:27:25Z"
>2035 October 3, 03:27</time
>
</div>
</header>
<!-- … -->
</article>An example HTML fragment, with Pagefind attributes for indicating what should be indexed (with data-pagefind-body), as well as ones for adding metadata.
The Pagefind documentation has detailed instructions on how these attributes are used.
Building a search interface
Pagefind comes with a pre-made search interface, which can be included in a page by loading one of the JavaScript files from the Pagefind binary's output. This interface is fine, but I wanted to build my own, partly because it'd be fun, and partly because I wanted the interface to better integrate with my website.
Building a custom search interface requires use of the Pagefind API. Fortunately, the API is fairly simple. A basic query can look like this:
const pagefind = await import("/search/pagefind/pagefind.js");
await pagefind.options({ bundlePath: "/search/pagefind/", baseUrl: "/" });
await pagefind.init();
const searchQuery = await pagefind.search("nixos");Executing a query for "nixos".
Both the init() call and the search() call involve network requests. init() causes Pagefind to load general metadata and configuration relating to the search database, as well as the relevant WebAssembly bytecode. Once init() is done, Pagefind can figure out which chunks of index it should download for a given query, and these are the requests that search() makes.
The object returned (within a promise) by the search() call does not, however, contain all the metadata for each result. Each potential result—which is to say, each page—has its own file containing both the metadata which Pagefind gathered, as well as the full searched text of the page. For each result, Pagefind can be asked to make a request for the corresponding file. The downside of this approach is the need to potentially make more requests to build a search results page, but the upsides are the fact that the client does not have to download metadata for pages that are not relevant. When using pagination, the client can also delay loading data for further pages, until it is needed.
Fetching the data for a single result looks like this:
const result = await searchQuery.results[0].data();
console.log(result.meta.date); // → "2023-08-30T13:56:17Z"
console.log(result.excerpt); // → "credentials and <mark>NixOS</mark> containers. 2023"Fetching the details of a single search result, including parsed metadata, and an excerpt.
Pagefind returns all the metadata fields as strings, which means something like the date field might need to be parsed back into a Date object.
Reusing pieces of Eleventy templates
When listing web log posts, my website uses a template fragment to render a post strip—a card which includes the publish date, the title, as well as a short summary of what the post is about. I use this on the front page, as well as on the page which lists all the published web log posts. It looks something like this:
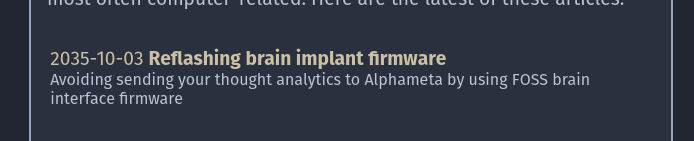
An example post strip, as it might appear on my front page, for preferred dark color scheme.
I wanted to reuse the post strip for search results that are blog posts. Using post strips there would both provide consistent design, and also supply some relevant information about what each result is—an excerpt highlighting relevant terms does not always provide that. Pagefind's metadata support provided an obvious means to supply the relevant fields needed for rendering the strip.
I was writing the search interface in vanilla JavaScript (to make it more fun), and ideally wanted to reuse the same partial template on the server side and the client side. This could be done with LiquidJS—which is one of the template engines that comes with Eleventy, and which is what I use for most of the site—but that would require the client to load the whole LiquidJS library (or at least a large portion of it), and that feels like overkill for a relatively simple partial template.
Eleventy also supports EJS. Since EJS supports pre-compiling templates, a template can potentially be used both from Eleventy at build time, and can also be bundled into the client-side JavaScript code for use there. The problem with doing this in practice is that a template written for use with Eleventy will end up using a bunch of Eleventy-supplied names and functions, and so it will not be easy to use from places outside Eleventy—like the client-side search script.
Plain JavaScript is another template format supported by Eleventy, however. Thus, one solution for creating a reusable EJS template is to create a JavaScript wrapper which loads a generic, reusable template, takes a bunch of data from Eleventy, and renders the template by putting that data into a shape that the template can use. This is the solution I decided to go with, and since I was no longer using Eleventy's built in EJS support anyway, I decided to employ Eta instead (which is supposed to be like EJS, but better). I added an Eleventy filter for rendering Eta templates:
const path = require("node:path");
const { Eta } = require("eta");
module.exports = (eleventyConfig) => {
const basePath = process.cwd();
const eta = new Eta({ views: basePath });
eleventyConfig.addAsyncFilter(
"renderEta",
async (templateFile, extra = {}) => {
return await eta.renderAsync(templateFile, extra);
}
);
};An Eleventy filter, renderEta, which renders an Eta template contained in a file.
A wrapper can then look something like this:
// ./includes/post-strip.11ty.js
const path = require("node:path");
module.exports = async function (input) {
const templateData = {
url: this.htmlBaseUrl(input.url, input.data.globalBaseUrl),
postDate: input.data.date,
postTitle: input.data.title,
postSummary: input.data.summary,
};
return await this.renderEta("./includes/eta/post-strip.eta", templateData);
};An Eleventy-specific wrapper for a generic Eta template.
I can then use renderFile to call the wrapper, from a place like the web log listing page:
{% for post in collections.blogpost reversed -%}
<li>
{% renderFile "./includes/post-strip.11ty.js", post %}
</li>
{%- endfor %}Fragment of a liquid template that iterates over web log posts and renders a post strip for each one, by calling the JavaScript wrapper
For the client side, I use Rollup to pre-compile the Eta template, and then have a function which takes a single Pagefind search result object, and renders a post strip out of it:
import postStrip from "./includes/eta/post-strip.eta";
// actually substituted as part of the build process
const baseUrl = "https://dee.underscore.world";
// …
function getBlogResultHtml(data) {
return postStrip({
url: new URL(data.url, baseUrl),
postDate: new Date(data.meta.date),
postTitle: data.meta.title,
postSummary: data.meta.summary,
excerpt: data.excerpt,
});
}Using the same post strip template, but from the client side
In more detail
For a more detailed example I have a branch of my Eleventy example repository that contains enough code to roughly reproduce what my actual website does for Pagefind.